
Published on 082323 Updated on 101123. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine. Llama 2 is a collection of pretrained and fine-tuned large language models LLMs ranging. Llama 2 is a family of pre-trained and fine-tuned large language models LLMs released by Meta AI in. . Llama 2 is a family of pre-trained and fine-tuned large language models LLMs ranging in scale from. The LLaMA and LLaMA 2 models are Generative Pretrained Transformer models based on the original..
Medium
All three model sizes are available on HuggingFace for download Llama 2 models download 7B 13B 70B Ollama Run create and share large language. Llama 2 70b stands as the most astute version of Llama 2 and is the favorite among users We recommend to use this variant in your chat. Use of this model is governed by the Meta license In order to download the model weights and tokenizer please visit the website and. Then you can run the script. We are releasing Code Llama 70B the largest and best-performing model in the Code..
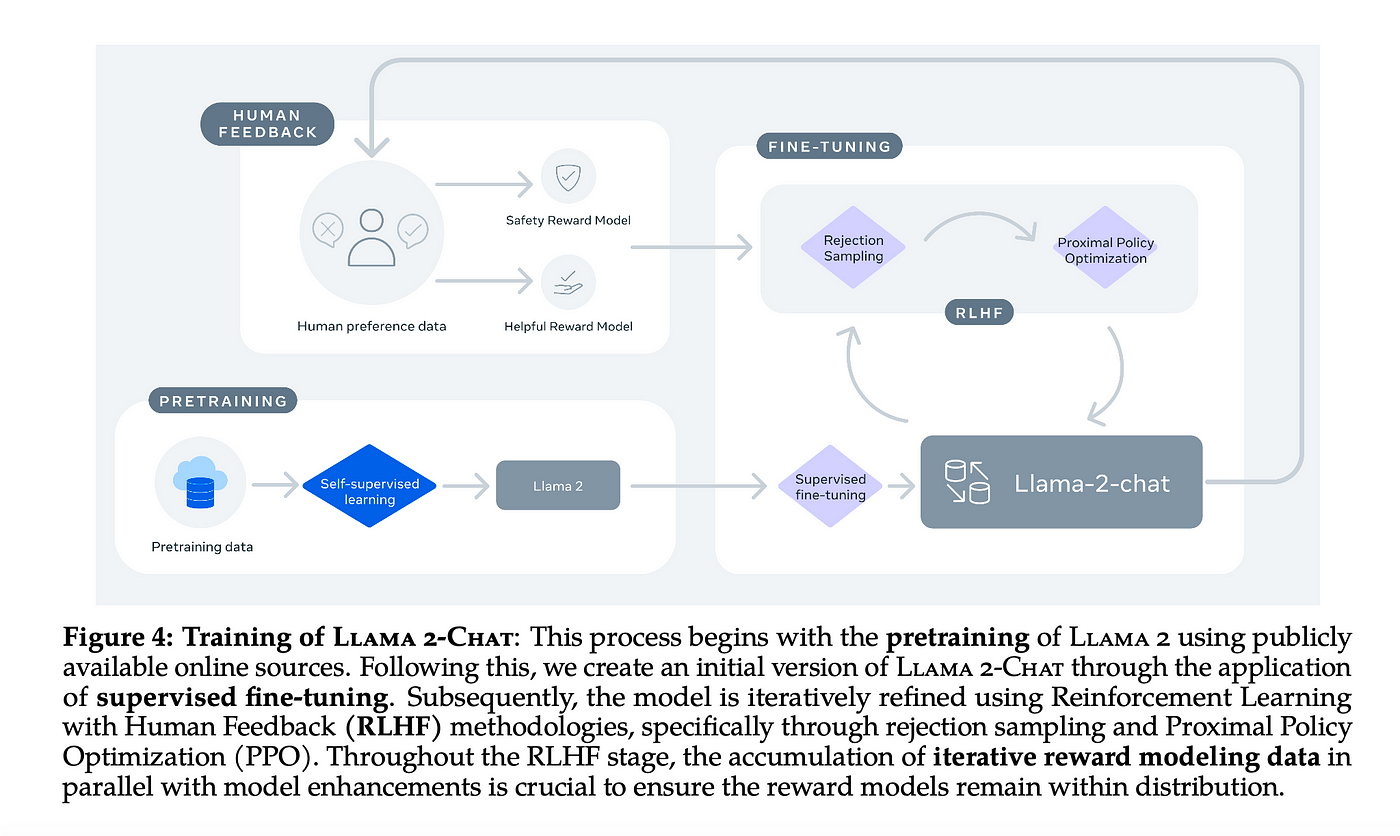
Open Foundation and Fine-Tuned Chat Models This work develops and releases Llama 2 a. . Open Foundation and Fine-Tuned Chat Models In this. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large. In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2. Open Foundation and Fine-Tuned Chat Models GenAI Team Meta Presented By. 2 Related Work Language Models for Chat Since the success of GPT-2 Radford et al2019 there have been many..

Deepgram
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large. . Like all LLMs Llama 2 is a new technology that carries potential risks with use. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large. Last week Meta introduced Llama 2 a new large. Today were introducing the availability of Llama 2 the next generation of our open source. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models..






Komentar